
7月7日,在2023世界人工智能大會期間,畢馬威和聯想集團聯合發布《“普慧”算力開啟新計算時代》報告,并指出大模型的真正價值最終將體現在具體場景中,未來產業競爭也會從“規模”轉向“應用”。通用人工智能若要真正走向落地,需要“普慧”算力推動大小模型協同進化。
畢馬威中國數字化賦能主管合伙人張慶杰表示,未來算力發展趨勢將具備兩大特征:數字經濟的基礎設施和通用人工智能的核心動力。因此,算力將在兩個關鍵維度上加速發展:普適(Inclusive)與智慧(Intelligent),即“普慧”。
“普慧”算力強調立足實際使用需求,安全合理的使用數據,以高效的算法,實現可靠的數字化、智能化效果。其中,“普”為“普適”,強調以自然交互的方式提供算力,算力將成為人人可得、人人可用、人人適用的“3A”型基礎資源,旨在讓人們即取即用算力而不必見;“慧”為“智慧”,強調以認知驅動的方式提供算力,算力將具備自適應、自學習、自進化為代表的“3S”智能,能夠讓人們隨需使用算力而不必問。
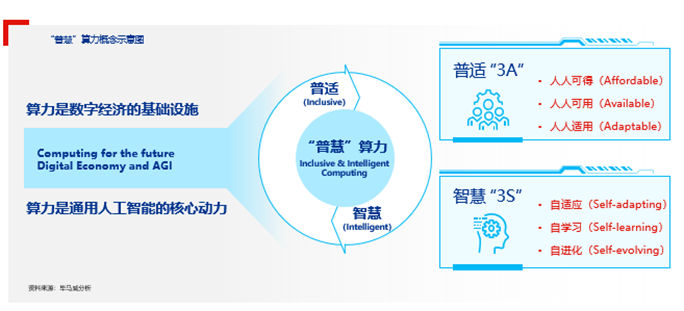
未來算力將在普適和智慧兩個維度上加速發展
自2022年底以來,從OpenAI的ChatGPT、谷歌的Bard,再到百度的“文心一言”、阿里云的“通義千問”……全球科技公司和機構紛紛推出大模型產品。據不完全統計,僅在國內,半年內就有81個大模型發布。
畢馬威認為,目前大模型訓練都在云端實現,所用算力是中心化的,精度要求高且成本高,意味著大模型落地必然會面臨能耗和性能平衡的難題。破局之道在于大小模型協同進化,即在利用大參數訓練完大模型之后,通過高精度壓縮,將大模型轉化為端側可用的小模型,大模型相當于超級大腦,小模型相當于垂直領域專家,共同推動AGI落到實處,這也是“普慧”算力釋放價值的過程。
此外,要想實現通用人工智能的落地,算力降本問題也迫在眉睫,而這也離不開大小模型的協同。放眼全球,當下除了科技巨頭外,幾乎沒有企業承擔得起大模型訓練的高昂成本。而算力降本并非減少投入,而是利用有限資金獲取更多元的算力。報告指出,在大模型走向場景化、實用化的過程中,將會形成“大模型+小模型”的產業生態,即大型企業負責搭建底層通用大模型,中小型企業在大模型的基礎上搭建面向特定任務場景的小模型,相較大模型而言,小模型訓練的資金投入更低,且更能滿足不同主體在不同階段、不同場景中的不同算力需求,小模型訓練需求的算力增量仍然可觀。
可以預見,隨著各行業全要素、全流程、全場景邁向數字化和智能化,數據架構和業務架構將不斷向更強大的算力平臺上遷移,實現“業務、數據、算力”之間的高效聯動,從而保證算力資源按需匹配、精準賦能,真正推動算力轉化為現實的生產力。













