
滴滴集團作為生活服務領域的頭部企業,正在全面測試和上線StarRocks。其中橙心優選經過一年多的數據體系建設,我們逐漸將一部分需要實時交互查詢、即席查詢的多維數據分析需求由ClickHouse遷移到了StarRocks中,StarRocks在穩定性、實時性方面也給了我們良好的體驗,接下來以StarRocks實現的漏斗分析為例介紹StarRocks在橙心優選運營數據分析應用中的實踐。
作者:王鵬 滴滴橙心優選數據架構部資深數據架構開發工程師,負責橙心優選大數據基礎服務和數據應用的開發與建設
需求介紹
當前我們數據門戶上的漏斗分析看板分散,每個看板通常只能支持一個場景的漏斗分析,不利于用戶統一看數或橫向對比等,看板無法支持自選漏斗步驟、下鉆拆解等靈活分析的功能。因此,我們需要一款能覆蓋更全的流量數據,支持靈活篩選維度、靈活選擇漏斗,提供多種分析視角的漏斗分析工具,并定位流失人群、轉化人群,從而縮小問題范圍,精準找到運營策略、產品設計優化點,實現精細化運營。
技術選型
電商場景的流量日志、行為日志一般會比傳統場景下的數據量大很多,因此在這樣的背景下做漏斗分析給我們帶來了兩大技術挑戰:
·日增數據量大:日增千萬級數據,支持靈活選擇維度,如何快速地對億級數據量進行多維分析
·對數據分析時效性要求高:如何快速地基于億級數據量精確去重,獲取符合條件的用戶數量
StarRocks與ClickHouse在橙心內部都有廣泛的應用,我們也積累了豐富的經驗,但StarRocks在易用性和可維護性上都比ClickHouse更勝一籌,下面這張表格是我們在使用過程中對兩者功能的一個簡單對比:

經過不斷地對比和壓測,我們最終決定使用StarRocks來存儲需要進行漏斗分析的數據,因為StarRocks在SQL監控、運維方面相比ClickHouse的優勢明顯,而且我們可以為了滿足不同的查詢場景,基于漏斗分析明細表創建各種各樣的物化視圖,提高多維數據分析的速度。
系統架構
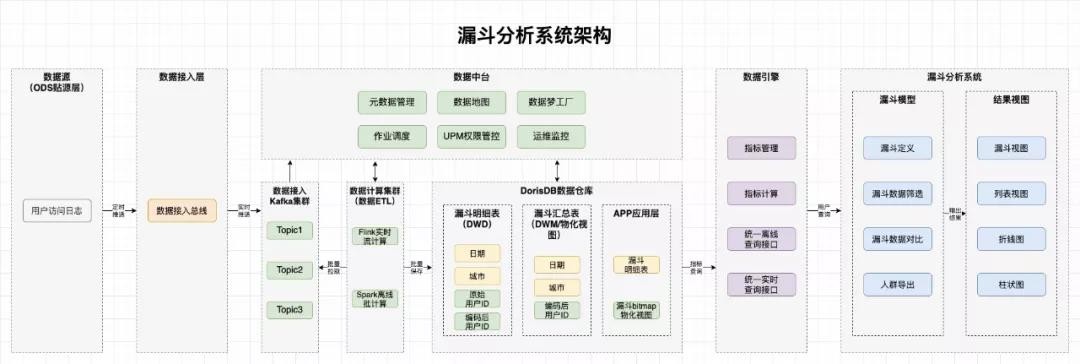
系統各層職責說明如下:
1、數據源:主要是web端、客戶端的埋點日志,這些埋點日志源源不斷地上傳給我們的數據接入層
2、數據接入層:
(1)數據接入總線:提供多種數據源的接入接口,接收并校驗數據,對應用層屏蔽復雜的數據格式,對埋點日志進行校驗和簡單地清洗、轉換后,將日志數據推送到Kafka集群
(2)Kafka集群:數據接入總線與數據計算集群的中間層。數據接入總線的對應接口將數據接收并校驗完成后,將數據統一推送給Kafka集群。Kafka集群解耦了數據接入總線和數據計算集群,利用Kafka自身的能力,實現流量控制,釋放高峰時日志數據量過大對下游計算集群、存儲系統造成的壓力
3、數據計算與存儲層:
(1)數據計算集群:數據存入Kafka集群后,根據不同的業務需求,使用Flink或者Spark對數據進行實時和離線ETL,并批量保存到StarRocks數據倉庫
(2)StarRocks數據倉庫:Spark+Flink通過流式數據處理方式將數據存入StarRocks,我們可以根據不同的業務場景在StarRocks里創建明細表、聚合表和更新表以及物化視圖,滿足業務方多樣的數據使用要求
4、數據服務層:內部統一指標定義模型、指標計算邏輯,為各個應用方提供統一的離線查詢接口和實時查詢接口
5、漏斗分析系統:支持靈活創建和編輯漏斗,支持漏斗數據查看,漏斗明細數據導出
6、數據中臺:圍繞大數據數據生產與使用場景,提供元數據管理、數據地圖、作業調度等通用基礎服務,提升數據生產與使用效率
詳細設計
目前,基于StarRocks的bitmap類型只能接受整型值作為輸入,由于我們原始表的user_id存在字母數字混合的情況,無法直接轉換成整型,因此為了支持bitmap計算,需要將當前的user_id轉換成全局唯一的數字ID。我們基于Spark+Hive的方式構建了原始用戶ID與編碼后的整型用戶ID一一映射的全局字典,全局字典本身是一張Hive表,Hive表有兩個列,一個是原始值,一個是編碼的Int值。以下是全局字典的構建流程:
1、將原始表的字典列去重生成臨時表:
臨時表定義:
create table 'temp_table'{
'user_id' string COMMENT '原始表去重后的用戶ID'
}
字典列去重生成臨時表:
insert overwrite table temp_table select user_id from fact_log_user_hive_table group by user_id
2、臨時表和全局字典進行left join,懸空的詞典項為新value,對新value進行編碼并插入全局字典:
全局字典表定義:
create table 'global_dict_by_userid_hive_table'{
'user_id' string COMMENT '原始用戶ID',
'new_user_id' int COMMENT '對原始用戶ID編碼后的整型用戶ID'
}
將臨時表和全局字典表進行關聯,未匹配中的即為新增用戶,需要分配新的全局ID,并追加到全局字典表中。全局ID的生成方式,是用歷史表中當前的最大的用戶ID加上新增用戶的行號:
--4 更新Hive字典表
insert overwrite global_dict_by_userid_hive_table
select user_id, new_user_id from global_dict_by_userid_hive_table
--3 與歷史的字段數據求并集
union all select t1.user_id,
--2 生成全局ID:用全局字典表中當前的最大用戶ID加上新增用戶的行號
(row_number() over(order by t1.user_id) + t2.max_id) as new_user_id
--1 獲得新增的去重值集合
from
(
select user_id from temp_table
where user_id is not null
) t1
left join
(
select user_id, new_user_id, (max(new_user_id) over()) as max_id from
global_dict_by_userid_hive_table
) t2
on
t1.user_id = t2.user_id
where t2.newuser_id is null
3、原始表和更新后的全局字典表進行left join,將新增用戶的ID和編碼后的整型用戶ID插入到原始表中:
insert overwrite fact_log_user_hive_table
select
a.user_id,
b.new_user_id
from
fact_log_user_hive_table a left join global_dict_by_userid_hive_table b
on a.user_id=b.user_id
4、創建Spark離線同步任務完成Hive原始表到StarRocks明細表的數據同步:StarRocks表fact_log_user_doris_table定義(Hive表fact_log_user_hive_table與該表的結構一致):
CREATE TABLE `fact_log_user_doris_table` (
`new_user_id` bigint(20) NULL COMMENT "整型用戶id",
`user_id` varchar(65533) NULL COMMENT "用戶id",
`event_source` varchar(65533) NULL COMMENT "端(1:商城小程序 2:團長小程序 3:獨立APP 4:主端)",
`is_new` varchar(65533) NULL COMMENT "是否新用戶",
`identity` varchar(65533) NULL COMMENT "用戶身份(團長或者普通用戶)",
`biz_channel_name` varchar(65533) NULL COMMENT "當天首次落地頁渠道名稱",
`pro_id` varchar(65533) NULL COMMENT "省ID",
`pro_name` varchar(65533) NULL COMMENT "省名稱",
`city_id` varchar(65533) NULL COMMENT "城市ID",
`city_name` varchar(65533) NULL COMMENT "城市名稱",
`dt` date NULL COMMENT "分區",
`period_type` varchar(65533) NULL DEFAULT "daily" COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`index_id`, `user_id`, `biz_channel_name`, `pro_id`, `city_id`)
PARTITION BY RANGE(`dt`)(
PARTITION p20210731 VALUES [('2021-07-31'), ('2021-08-01')),
PARTITION p20210801 VALUES [('2021-08-01'), ('2021-08-02')),
PARTITION p20210802 VALUES [('2021-08-02'), ('2021-08-03')),
PARTITION p20210803 VALUES [('2021-08-03'), ('2021-08-04')),
PARTITION p20210804 VALUES [('2021-08-04'), ('2021-08-05')),
PARTITION p20210805 VALUES [('2021-08-05'), ('2021-08-06')),
PARTITION p20210806 VALUES [('2021-08-06'), ('2021-08-07')),
PARTITION p20210807 VALUES [('2021-08-07'), ('2021-08-08')),
PARTITION p20210808 VALUES [('2021-08-08'), ('2021-08-09')))
DISTRIBUTED BY HASH(`index_id`, `user_id`) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "1",
"dynamic_partition.prefix" = "p",
"dynamic_partition.replication_num" = "-1",
"dynamic_partition.buckets" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
在這里我們使用了StarRocks的明細模型來建表,滿足用戶查詢漏斗明細數據的使用場景,在明細表上根據不同的多維漏斗分析查詢需求創建相應的物化視圖,來滿足用戶選擇不同維度查看漏斗模型每一步驟用戶精確去重數量的使用場景。
5、創建bitmap_union物化視圖提升查詢速度,實現count(distinct)精確去重:
由于用戶想要在漏斗模型上查看一些城市用戶轉化情況。
查詢一般為:
select city_id, count(distinct new_user_id) as countDistinctByID from fact_log_user_doris_table where `dt` >= '2021-08-01' AND `dt` <= '2021-08-07' AND `city_id` in (11, 12, 13) group by city_id
針對這種根據城市求精確用戶數量的場景,我們可以在明細表fact_log_user_doris_table上創建一個帶 bitmap_union 的物化視圖從而達到一個預先精確去重的效果,查詢時StarRocks會自動將原始查詢路由到物化視圖表上,提升查詢性能。針對這個case創建的根據城市分組,對user_id進行精確去重的物化視圖如下:
create materialized view city_user_count as select city_id,bitmap_union(to_bitmap(new_user_id)) from fact_log_user_doris_table group by city_id;
在StarRocks中,count(distinct)聚合的結果和bitmap_union_count聚合的結果是完全一致的。而bitmap_union_count等于bitmap_union的結果求 count,所以如果查詢中涉及到count(distinct) 則通過創建帶bitmap_union聚合的物化視圖方可加快查詢。因為new_user_id本身是一個INT類型,所以在 StarRocks 中需要先將字段通過函數to_bitmap轉換為bitmap類型然后才可以進行bitmap_union聚合。
采用這種構建全局字典的方式,我們通過每日凌晨跑Spark離線同步任務實現全局字典的更新,以及對原始表中 Value 列的替換,同時對Spark任務配置基線和數據質量報警,保障任務的正常運行和數據的準確性,確保次日運營和市場同學能看到之前的運營活動對用戶轉化率產生的影響,以便他們及時調整運營策略,保證日常運營活動效果。
最終效果及收益
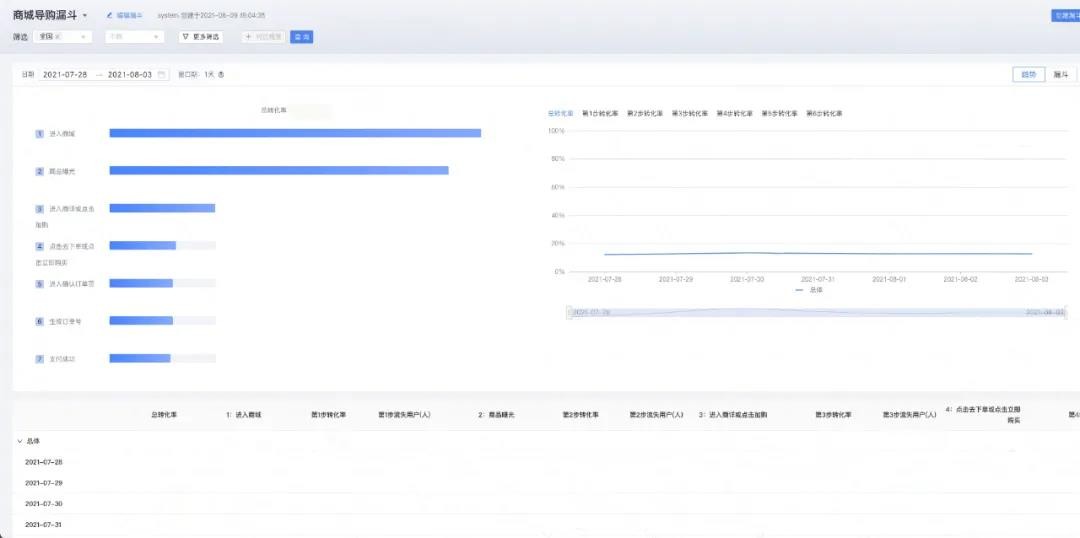
經過產品和研發同學的共同努力,我們從需要查詢的城市數量、時間跨度、數據量三個維度對精確去重功能進行優化,億級數據量下150個城市ID精確去重查詢整體耗時3秒以內,以下是漏斗分析的最終效果:
未來規劃
1.完善StarRocks內部工具鏈的開發,同滴滴大數據調度平臺和數據開發平臺整合,實現MySQL、ES、Hive等數據表一鍵接入StarRocks。
2.StarRocks流批一體建設,由于StarRocks提供了豐富的數據模型,我們可以基于更新模型和明細模型以及物化視圖構建流批一體的數據計算與存儲模型,目前正在方案落地階段,完善后會推廣到橙心各個方向的數據產品上。
3.基于StarRocks On ElasticSearch的能力,實現異構數據源的統一OLAP查詢,賦能不同場景的業務需求,加速數據價值產出。
后續我們也會持續關注StarRocks,在內部不斷的升級迭代。期待StarRocks能提供更豐富的功能,和更開放的生態。StarRocks后續也會作為OLAP平臺的重要組件,實現OLAP層的統一存儲,統一分析,統一管理。













